Apache GeaFlow (Incubating) 时序能力探秘——让时间数据焕发新生!
为什么时序能力如此重要?
在当今数字化时代,数据已经成为驱动决策和创新的核心资源。然而,数据不仅仅是静态的数字或关系,它会随着时间不断变化。无论是股票市场的实时波动、社交网络中的动态互动,还是物联网设备的状态更新,时间维度都是理解这些数据的关键,例如:
- 在金融领域,交易的时间顺序决定了资金流动的方向。
- 在社交网络中,用户的互动行为(如点赞、评论)随时间演变。
- 在物联网中,传感器采集的数据带有时间戳,反映了设备状态的变化。
尽管数据的重要性毋庸置疑,但传统的图数据分析工具往往难以应对动态数据的挑战
- 静态分析的局限性
静态分析只能捕捉某一时刻的数据快照,无法反映数据的变化趋势。例如,在监控设备状态时,静态分析可能忽略设备从正常到故障的渐变过程。
- 处理效率低下
传统工具在处理大规模时序数据时效率低下,甚至无法满足实时需求。例如,在金融风控场景中,延迟可能导致错过关键的风险信号。
- 缺乏灵活性
很多工具只支持单一类型的数据分析,无法同时处理实时流数据和历史数据。
为了解决上述问题,Apache GeaFlow (Incubating) 创新性地提出了时序图计算的概念。作为一款专为动态图数据处理设计的分布式流图计算引擎,GeaFlow 能够高效应对动态数据带来的挑战。针对实时变化的图结构,用户可以轻松进行图遍历、图匹配和图计算等操作,从而满足复杂场景下的分析需求。通过结合时间维度与动态图处理能力,GeaFlow 为实时数据分析提供了全新的解决方案,帮助用户更精准地挖掘动态数据中的价值。
什么是 Apache GeaFlow (Incubating)?
Apache GeaFlow (Incubating) 是一个强大的分布式计算平台,结合了图计算和流处理的优势,能够高效处理动态图和时序数据。它不仅支持复杂的图算法,还具备实时分析能力,适用于各种动态场景。其主要特点包括:
- 分布式架构
Apache GeaFlow (Incubating) 基于分布式计算框架,能够高效处理超大规模的动态图数据(例如数十亿节点和边)。通过分区和副本机制,GeaFlow 确保了系统的高可用性和可扩展性。
- 流图与时序图的无缝集成
流图提供了动态数据的实时更新能力,而时序图则引入了时间维度的精确记录能力。两者的结合使得 GeaFlow 能够同时支持实时分析和历史追溯。
- 灵活的时间窗口机制
GeaFlow 支持基于时间窗口的动态分析,用户可以根据需求设置滑动窗口或固定窗口,分析特定时间段内的数据变化趋势。
流图与时序图的关系?
1. 流图(Stream Graph)
流图是一种特殊的图结构,用于表示动态数据的演化过程。其核心特性包括:
- 动态更新机制
流图支持节点和边的动态增删改操作,能够实时反映数据的变化。例如,在金融交易网络中,资金流动会生成新的边,而交易完成后某些边可能会消失。
- 事件驱动模型
流图采用事件驱动模型,每条数据(节点或边)都被视为一个事件。通过事件驱动的方式,流图能够高效捕捉数据的变化。
- 增量计算
为了提高计算效率,流图采用了增量计算策略。即每次只计算新增或修改的部分,而不是重新计算整个图结构。例如,在社交网络中,当用户建立新的好友关系时,GeaFlow 只需更新相关部分,而无需重新计算整个网络。
2. 时序图(Temporal Graph)
时序图是一种带时间属性的图结构,每条边或节点都带有时间戳,用于记录事件发生的时间。其核心特性包括:
- 时间戳管理
每条数据(节点或边)都分配一个时间戳,确保所有操作都能精确记录时间信息。例如,在社交网络中,好友关系的建立时间可以用一条带时间戳的边表示。
- 时间窗口分析
时序图支持基于时间窗口的分析功能。例如,用户可以设置一个滑动窗口(如最近 5 分钟),并分析窗口内的数据变化趋势。
- 历史追溯能力
时序图保留了历史数据的时间戳信息,支持回溯历史数据。例如,在金融风控场景中,用户可以通过时序图分析过去一段时间内的异常交易行为。
3. 流图与时序图的关系
流图和时序图并不是相互独立的概念,而是相辅相成的:
- 流图是时序图的基础
流图提供了动态数据的实时更新能力,而时序图则在此基础上增加了时间维度的记录能力。换句话说,流图关注的是数据的实时变化,而时序图关注的是这些变化的时间属性。
- 时序图增强了流图的分析能力
通过引入时间戳,时序图使得流图能够进行更复杂的分析,例如时间窗口分析、趋势预测等。
4. Apache GeaFlow (Incubating) 的实现细节
GeaFlow 通过以下技术手段实现了流图与时序图的无缝结合:
- 时间戳分配机制
GeaFlow 为每条数据(节点或边)分配具体时间戳, 具体分为两种:处理时间和事件时间,确保所有数据都能精确记录时间信息。
- 动态更新与历史保留
GeaFlow 支持实时更新流图结构,同时保留历史数据的时间戳信息,方便后续分析。例如,在金融交易网络中,GeaFlow 会记录每笔交易的时间戳,并将其存储在分布式存储系统中。
- 时间窗口优化
GeaFlow 采用高效的索引机制和缓存策略,优化时间窗口分析的性能。例如,通过滑动窗口索引,GeaFlow 能够快速定位特定时间段内的数据。
示例
随着社交媒体平台的快速发展,用户之间的互动和关系链变得越来越复杂。为了更好地理解用户行为、优化推荐系统以及识别潜在的风险(如虚假账号或恶意传播),我们需要对用户之间的动态关系进行实时分析。
假设某社交平台希望实现一个功能:实时追踪用户的“间接好友关系”,即分析用户 A 是否通过某个共同好友 B 认识了另一个用户 C,并确保这种认识关系的时间顺序是合理的(A 先认识 B,B 再认识 C)。这一功能可以帮助平台发现潜在的社交圈层,优化好友推荐算法,同时为风险控制提供数据支持。
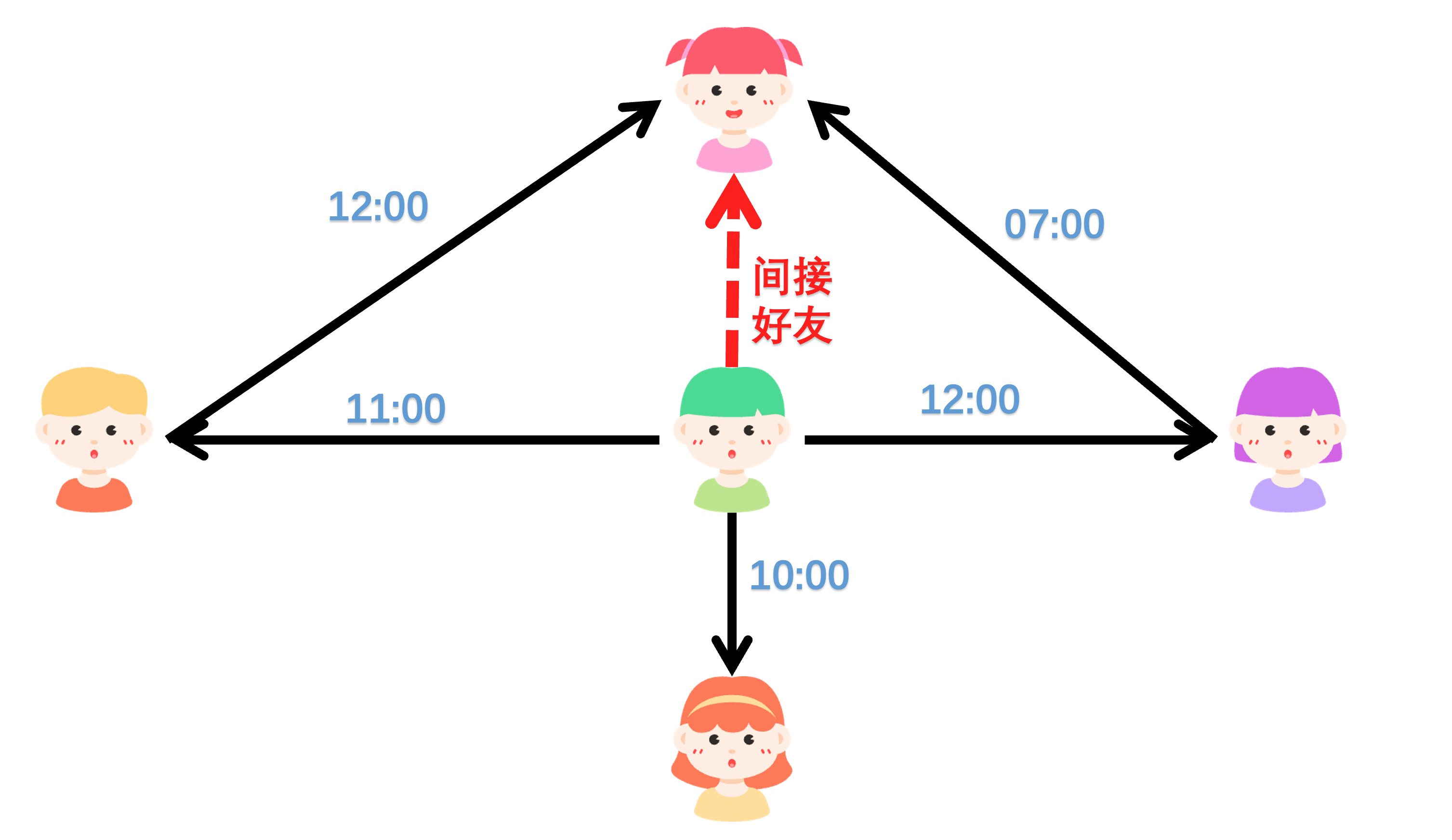
1、实时性要求
用户的行为(如添加好友)是动态变化的,需要实时捕获并更新用户关系图。
2、时间敏感性
好友关系的建立是有时间顺序的,例如用户 A 在 10:00 添加了用户 B 为好友,而用户 B 在 10:05 添加了用户 C 为好友。只有在这种情况下,我们才能认为 A 通过 B 间接认识了 C。
3、高效查询
平台需要快速查询出所有符合条件的三元关系(A -> B -> C),并将结果存储到文件系统中,供后续分析或可视化使用。
4、扩展性
系统需要能够处理大规模用户数据,并支持未来的扩展需求,例如引入更多维度的关系权重(如亲密度、互动频率等)。
下面是完整的 DSL 示例:
CREATETABLE vertex_source (
id long,
name varchar,
age int
) WITH (
type='kafka',
geaflow.dsl.kafka.servers ='localhost:9092',
geaflow.dsl.kafka.topic ='vertex_source',
geaflow.dsl.kafka.data.operation.timeout.seconds =5,
geaflow.dsl.time.window.size=10,
geaflow.dsl.start.time='${startTime}'
);
CREATETABLE edge_source (
src_id long,
tar_id long,
weight double,
ts long --knowing time
) WITH (
type='kafka',
geaflow.dsl.kafka.servers ='localhost:9092',
geaflow.dsl.kafka.topic ='edge_source',
geaflow.dsl.kafka.data.operation.timeout.seconds =5,
geaflow.dsl.time.window.size=10,
geaflow.dsl.start.time='${startTime}'
);
CREATE GRAPH community (
Vertex person (
id bigint ID,
name varchar,
age int
),
Edge knows (
src_id bigint SOURCE ID,
tar_id bigint DESTINATION ID,
weight double,
ts long TIMESTAMP--定义时间戳字段
)
) WITH (
storeType='rocksdb'
);
INSERTINTO community.person
SELECT id, name, age
FROM vertex_source;
INSERTINTO community.knows
SELECT src_id, tar_id, weight, ts
FROM edge_source;
CREATETABLE tbl_result (
a_id long,
e1_ts long,
b_id long,
e2_ts long,
c_id long
) WITH (
type='file',
geaflow.dsl.file.path='${target}'
);
USE GRAPH community;
INSERTINTO tbl_result
SELECT
a_id,
e1_ts,
b_id,
e2_ts,
c_id
FROM (
MATCH (a:person)-[e1:knows]->(b:person)-[e2:knows]-> (c:person)
where e2.ts > e1.ts
RETURN a.id as a_id, e1.ts as e1_ts, b.id as b_id, e2.ts as e2_ts, c.id as c_id
);
上述 DSL(Domain-Specific Language)代码定义了一个基于图计算的流处理任务,主要目的是通过 Kafka 实时接收用户节点和关系边的数据流,构建一个动态社区图(<font style="color:rgb(63, 63, 63);background-color:rgb(214, 214, 214);">community</font>),并分析其中的时间敏感关系(如“谁先认识谁”)。最终结果将输出到文件系统中,用于进一步分析或可视化。
以下是对每个部分的详细解释:
1. 点源表定义
CREATETABLE vertex_source (
id long,
name varchar,
age int
) WITH (
type='kafka',
geaflow.dsl.kafka.servers ='localhost:9092',
geaflow.dsl.kafka.topic ='vertex_source',
geaflow.dsl.kafka.data.operation.timeout.seconds =5,
geaflow.dsl.time.window.size=10,
geaflow.dsl.start.time='${startTime}'
);
-
功能:
- 定义了一个名为vertex_source的表,表示点数据的来源。 _ 数据通过 Kafka 消费,主题为 vertex_source。 * 每条记录包含三个字段:id(节点唯一标识符)、name(节点名称)、age(节点年龄)。
-
时间窗口:
- 使用了滑动窗口机制,窗口大小为 10 秒(geaflow.dsl.time.window.size=10)。
- 数据流按时间窗口分批处理,窗口内的数据会被用于后续的图构建和计算。
-
启动时间: * ${startTime}是一个占位符,表示流处理任务的起始时间。
2. 边源表定义
CREATE TABLE edge_source (
src_id long,
tar_id long,
weight double,
ts long
) WITH (
type='kafka',
geaflow.dsl.kafka.servers = 'localhost:9092',
geaflow.dsl.kafka.topic = 'edge_source',
geaflow.dsl.kafka.data.operation.timeout.seconds = 5,
geaflow.dsl.time.window.size=10, -- 滑动窗口大小
geaflow.dsl.start.time='${startTime}'
);
- 功能:
- 定义了一个名为 edge_source的表,表示边数据的来源。
- 数据通过 Kafka 消费,主题为 edge_source。
- 每条记录包含四个字段: src_id和 tar_id:分别表示边的起点和终点;weight:边的权重;ts:边的时间戳,表示关系建立的时间。
- 时间窗口:
- 同样使用 10 秒的滑动窗口机制。
3. 图 Schema 定义
CREATE GRAPH community (
Vertex person (
id bigint ID,
name varchar,
age int
),
Edge knows (
src_id bigint SOURCE ID,
tar_id bigint DESTINATION ID,
weight double,
ts long TIMESTAMP-- 定义时间戳字段
)
) WITH (
storeType='rocksdb'
);
- 功能:
- 定义了一个名为community的图结构。
- 图包含两种元素:
- **点类型 **person:
- 每个点有三个属性:id(唯一标识符)、name(名称)、age(年龄)。
- **边类型 **knows:
- 每条边有四个属性:src_id和 tar_id:分别表示边的起点和终点;weight:边的权重;ts:边的时间戳,标记关系建立的时间。
- 存储方式:
- 图数据存储在 RocksDB 中(storeType='rocksdb')。
4. 插入点数据到图
INSERTINTO community.person
SELECT id, name, age
FROM vertex_source;
- 功能:
- 将 vertex_source表中的点数据插入到图 community的 person点集合中。
- 每条记录对应一个person节点。
5. 插入边数据到图
INSERTINTO community.knows
SELECT src_id, tar_id, weight, ts
FROM edge_source;
- 功能:
- 将 edge_source表中的边数据插入到图 community的 knows边集合中。
- 每条记录对应一条 knows边。
6. 结果表定义
CREATE TABLE tbl_result (
a_id long,
e1_ts long,
b_id long,
e2_ts long,
c_id long
) WITH (
type='file',
geaflow.dsl.file.path='${target}'
);
- 功能:
- 定义了一个名为 tbl_result 的结果表,用于存储最终的查询结果。
- 结果表包含五个字段:a_id:路径起点节点的 ID;e1_ts:第一条边的时间戳;b_id:路径中间节点的 ID;e2_ts:第二条边的时间戳;c_id:路径终点节点的 ID.
- 存储方式:
- 结果会写入文件系统,路径由 ${target} 指定。
7. 图查询与结果插入
USE GRAPH community;
INSERT INTO tbl_result
SELECT
a_id,
e1_ts,
b_id,
e2_ts,
c_id
FROM (
MATCH (a:person) -[e1:knows]->(b:person) -[e2:knows]-> (c:person)
WHERE e2.ts > e1.ts
RETURN a.id as a_id, e1.ts as e1_ts, b.id as b_id, e2.ts as e2_ts, c.id as c_id
);
- 功能:
- 在图 community 上执行一个图查询。
- 查询的目标是找到所有满足以下条件的三元组 (a, b, c):
- 存在一条路径 a -> b -> c,其中每条边的类型都是 knows。
- 第二条边 e2 的时间戳晚于第一条边 e1 的时间戳(e2.ts > e1.ts)。
- 返回的结果包括:
- 起点节点 a 的 ID。
- 第一条边 e1 的时间戳。 + 中间节点 b 的 ID。
- 第二条边 e2 的时间戳。
- 终点节点 c 的 ID。
- 结果存储:
- 查询结果被插入到 tbl_result 表中,并最终写入文件系统。
8. 运行示例
假设社交平台中有以下用户和好友关系:
- 用户信息:
{id: 1, name: "Alice", age: 25}
{id: 2, name: "Bob", age: 30}
{id: 3, name: "Charlie", age: 28}
- 好友关系:
{src_id: 1, tar_id: 2, weight: 0.8, ts: 1672531200} -- Alice 在 10:00 添加 Bob 为好友
{src_id: 2, tar_id: 3, weight: 0.9, ts: 1672531210} -- Bob 在 10:05 添加 Charlie 为好友
运行上述作业后,系统会输出以下结果:
a_id | e1_ts | b_id | e2_ts | c_id
1 | 1672531200 | 2 | 1672531210 | 3
这表明 Alice 先通过 Bob 认识了 Charlie。
9. 业务价值
-
优化好友推荐 通过分析间接好友关系,平台可以向用户推荐更有可能成为好友的潜在对象。例如,Alice 可能会对 Charlie 感兴趣,因为他们有一个共同好友 Bob。
-
识别社交圈层
通过挖掘三元关系,平台可以识别出紧密联系的社交圈层,从而为广告投放、活动推广等提供精准的目标群体。 -
风险控制
如果某些用户频繁出现在异常的三元关系中(例如短时间内大量新增好友),可能暗示存在虚假账号或恶意传播行为,平台可以及时采取措施。 -
用户体验提升
实时分析用户关系链,帮助平台更好地理解用户行为,从而提供更加个性化的服务。
10. 技术优势
- 实时性:Apache GeaFlow (Incubating) 支持毫秒级的数据流处理,确保用户关系图始终是最新的。
- 时间敏感性:通过时间戳字段,精确管理好友关系的时间顺序。
- 灵活性:SQL 驱动的开发模式,降低了开发门槛,提升了开发效率。
- 可拓展性:支持大规模动态图的增量计算,能够轻松应对社交平台的海量用户数据。
Apache GeaFlow (Incubating) 时序能力的核心亮点
1. 时间感知的数据处理
每条数据都带有时间戳,能够精确记录事件发生的时间。Apache GeaFlow (Incubating) 支持基于时间窗口的分析,例如:
-
最近 5 分钟的趋势变化 用户可以通过设置时间窗口,分析最近 5 分钟内的数据变化趋势。例如,在社交网络中,分析用户互动的频率变化。
-
过去一天的动态模式
Apache GeaFlow (Incubating) 支持长时间跨度的分析,帮助用户发现长期趋势。例如,在电商推荐系统中,分析用户在过去一天内的购买行为。
2. 动态图与时序结合
Apache GeaFlow (Incubating) 将图结构与时间维度结合,能够捕捉图中关系的演变。例如:
- 社交网络中好友关系的变化
在社交网络中,用户的好友关系可能会随着时间发生变化。GeaFlow 可以动态更新图结构,捕捉这些变化。 - 金融交易网络中的资金流动
在金融交易网络中,资金流动是一个动态过程。GeaFlow 可以实时追踪资金流动路径,并识别潜在的风险点。
3. 实时与历史数据的无缝融合
Apache GeaFlow (Incubating) 不仅支持实时流数据的处理,还能结合历史数据进行对比分析。这种能力特别适合需要长期趋势分析和短期实时监控的场景。例如:
- 物联网设备监控
在物联网场景中,GeaFlow 可以实时监控设备状态,同时结合历史数据,预测设备可能出现的故障。 - 金融风控
在金融风控场景中,GeaFlow 可以实时监控交易网络,同时结合历史数据,识别异常行为或潜在风险。
4. 丰富的内置算法
Apache GeaFlow (Incubating) 提供针对时序数据优化的算法,例如:
- 最短路径
- 弱联通分量
- k-hop 算法
用户无需从零开发,直接调用即可完成复杂分析。
结语:开启你的时序数据分析之旅
数据的动态变化蕴藏着无限价值,而 GeaFlow 的时序能力正是解锁这一价值的钥匙。无论您是数据分析新手,还是希望提升动态数据处理能力的专业人士,GeaFlow 都将为您提供强大的支持。
立即下载 GeaFlow,亲身体验其时序能力的强大之处吧!让我们一起探索时间数据的无限可能!
术语
DSL: Domain-Specific Language。融合 DSL 是 Apache GeaFlow (Incubating) 提供的图表一体的数据分析语言,支持标准 SQL+ISO/GQL 进行图表分析.通过融合 DSL 可以对表数据做关系运算处理,也可以对图数据做图匹配和图算法计算,同时也支持同时图表数据的联合处理。