流式图计算引擎 Apache GeaFlow (Incubating) v0.6.4 发布,支持关系型访问图数据,增量匹配优化实时处理
2025 年 3 月发布了流式图计算引擎 Apache GeaFlow (Incubating) v0.6.4,新版本实现了多个重要特性更新,包括:
- 🍀GeaFlow 图存储扩展支持 paimon 数据湖(实验性功能)
- 🍀图数仓能力扩展:支持对图中的实体进行关系型访问
- 🍀统一的内存管理器支持
- 🍀RBO 规则扩展:新增 MatchEdgeLabelFilterRemoveRule 和 MatchIdFilterSimplifyRule
- 🍀支持增量匹配算子
✨ 新增功能
🍀Apache GeaFlow (Incubating) 图存储扩展支持 paimon 数据湖(实验性功能)
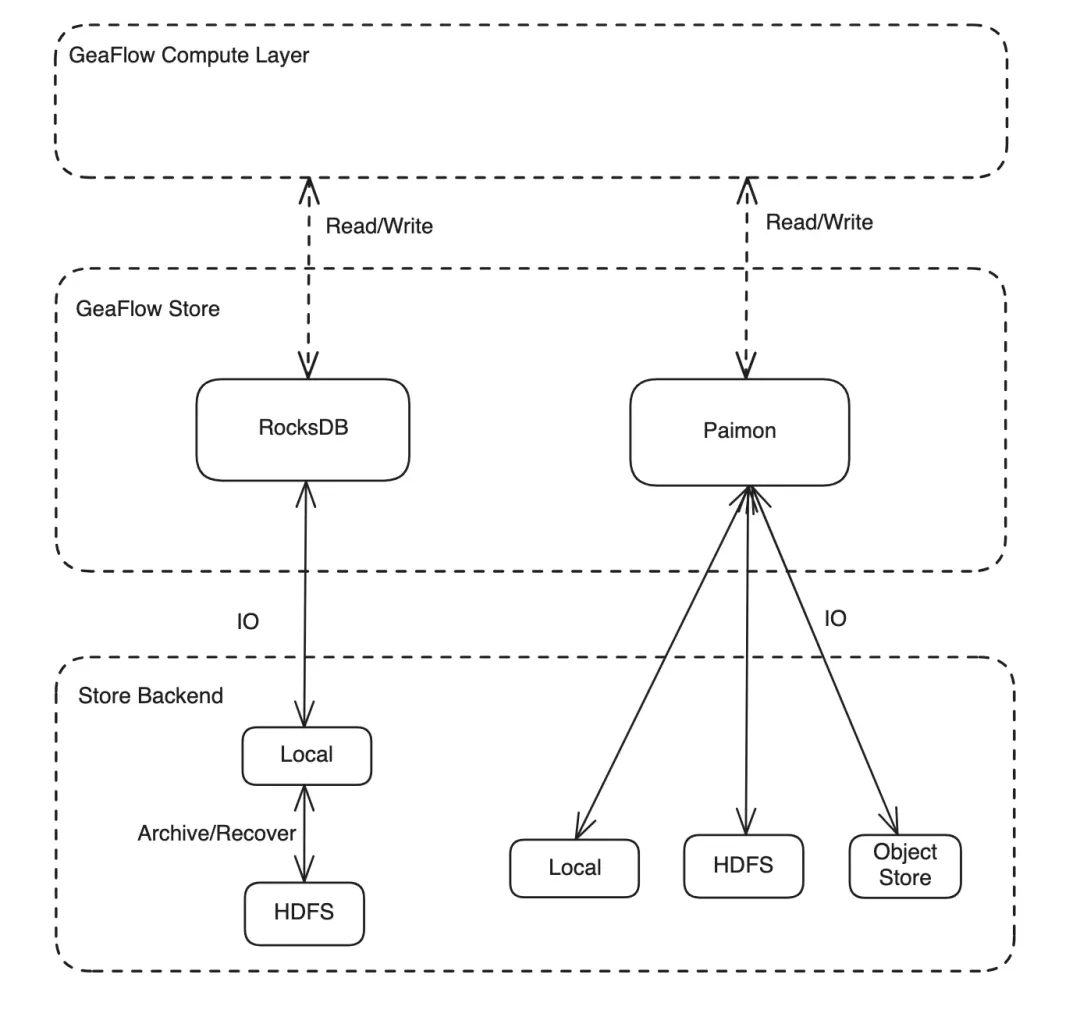
为提升 GeaFlow 数据存储系统的扩展性、实时数据处理能力及成本效率,本次更新加入了对 Apache Paimon 的支持。Paimon 作为新一代流式数据湖存储格式,在设计理念、功能特性上,与 GeaFlow 之前使用的 RocksDB 存在许多差异:
- 支持对象存储/HDFS 分布式存储,天然适配云原生环境。因此可实现存储与计算分离,降低硬件依赖,支持弹性扩展。
- 支持主键表 LSM 合并、增量更新,满足实时数据更新需求。
- 列式存储+统计索引(Z-Order、Min-Max 等),支持高效数据裁剪与 OLAP 查询加速。
在本次更新中,GeaFlow 加入了对 Paimon 存储的支持,但目前仅为实验性质。
- 支持在 GeaFlow 中将用户图数据存储到 paimon 数据湖。
- 当前为实验性功能,仅支持使用本地文件系统作为 paimon 的存储后端,且暂不支持 recover 能力,暂不支持动态图数据存储。
- 通过配置
geaflow.store.paimon.options.warehouse参数来指定存储路径,默认路径为"file:///tmp/paimon/"。
当前 Apache GeaFlow (Incubating) 的存储架构图如下。
🍀图数仓能力扩展:支持对图中的实体进行关系型访问
在传统关系型数据库中,多层表关联查询往往需要编写复杂的 JOIN 语句,不仅开发效率低下,性能也难以满足海量关联数据的即席分析需求。针对这一痛点,我们通过创新的 SQL 支持,让用户无需学习图查询语言(GQL)即可将 SQL 中复杂的 JOIN 语句自动转换为图路径查询。当前版本提供以下两种 SQL 语法支持:
- 支持图中的点/边作为 SQL 查询的来源表,进行查询。
- 我们通过 TableScanToGraphRule 规则,让生成和优化 RelNode 时识别 SQL 语句中来源于图中的点/边实体,这使得用户可以像 SQL 中扫表操作一样读取图中的点边
- 示例: student 是图 g_student 中的点实体
USE GRAPH g_student;
INSERT INTO table_scan_001_result
select avg(age) as avg_age from student;
- 支持图中的点与边关联作为 SQL 查询的等值条件 Join,进行查询。
- 我们通过 TableJoinTableToGraphRule 规则,让生成和优化 RelNode 时识别 SQL 语句中的 Join 算子,这使得用户可以像 SQL 中连接表操作一样在图中进行查询
- 示例: student 是图 g_student 中的点实体,selectCource 是关联在 student 点上的出边
USE GRAPH g_student;
INSERT INTO vertex_join_edge_001_result
SELECT s.id, sc.targetId, sc.ts
FROM student s JOIN selectCourse sc on s.id = sc.srcId
WHERE s.id < 1004
ORDER BY s.id, targetId
;
🍀内存管理器支持
当前 GeaFlow 没有内存管理,除了外部依赖 rocksdb 会用堆外内存,其他的全都是堆内内存。当内存使用多时,GC 压力明显,另外 shuffle 阶段网络发送也存在多次数据拷贝,导致效率不高。
内存管理负责各模块(shuffle、state、framework)的内存管控,包括申请、释放、监控。 内存管理有两部分:堆内和堆外。不同模块使用可能不同的内存区域,合理使用这些资源可以更高效跑完作业。内存管理器主要有以下核心能力:
- 支持堆内和堆外内存统一管理:通过统一抽象 MemoryView,提供读写接口,屏蔽用户对堆外和堆外的感知。当前 Memoryview 堆外内存是采用预分配模式,初始大小是通过 off.heap.memory.chunkSize.MB 参数来控制,如果不设置,默认是 -Xmx 参数的 30%作为初始值。运行过程中也支持动态扩所容。
- 支持计算和存储统一内存管理
为了避免堆外内存浪费或者过度使用,GeaFlow 对各模块的堆外内存使用统一管理。内存主要分 3 个部分:shuffle、state 和 default。 Default 是预留空间,可动态被 shuffle 或者 state 模块占用。 如下图所示:
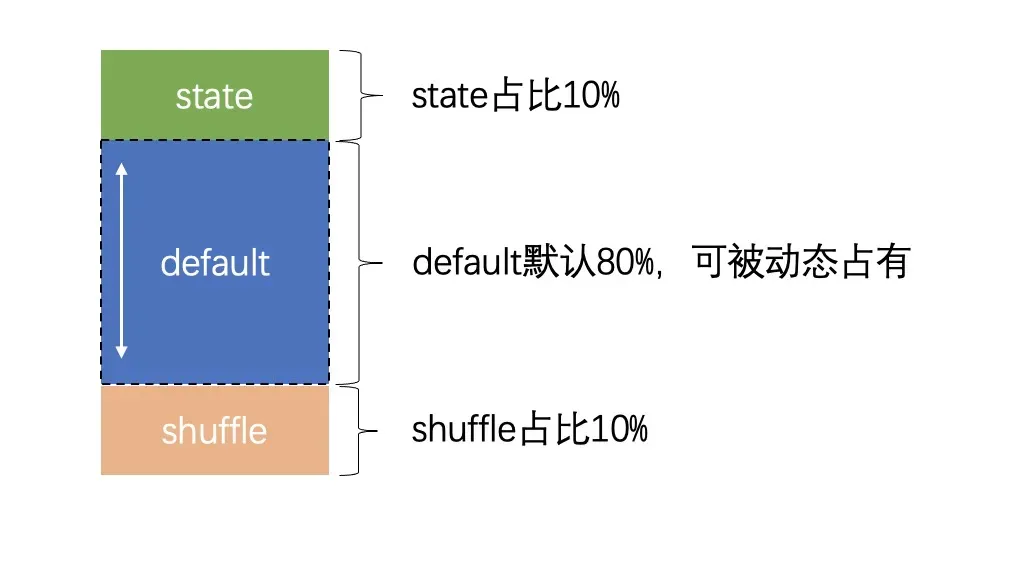state 和 shuffle 默认独占 10%的堆外内存, default 则占用 80%。
🍀RBO 规则扩展:新增 EdgeLabel 和 IdFilter 优化规则
- Edge Label 简化:针对 Match 匹配语句后接 Where 子句对边进行过滤的查询进行执行计划简化。
- ID Filter 简化:针对 Match 匹配语句中对点的 id 进行过滤的查询进行执行计划简化。
- 规则在默认情况下生效,使用示例如下:
// GQL示例1(MatchIdFilterSimplifyRule优化)
MATCH (a:user where id = 1)-[e:knows]-(b:user)
RETURN a.id as a_id, e.weight as weight, b.id as b_id
// 原执行计划
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user) where =(a.id, 1) -[e:knows]-(b:user)])
LogicalGraphScan(table=[default.g0])
// MatchIdFilterSimplifyRule优化后执行计划,vertex id转移到MatchVertex中进行过滤
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user)-[e:knows]-(b:user)])
LogicalGraphScan(table=[default.g0])
// GQL示例2(MatchEdgeLabelFilterRemoveRule优化)
MATCH (a:user where id = 1)-[e:knows]-(b:user) WHERE e.~label = 'knows'
or e.~label = 'created'
RETURN a.id as a_id, e.weight as weight, b.id as b_id
// 原执行计划
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user) where =(a.id, 1) -[e:knows]-(b:user) where OR(=($1.~label, _UTF-16LE'knows'), =($1.~label, _UTF-16LE'created')) ])
LogicalGraphScan(table=[default.g0])
// MatchEdgeLabelFilterRemoveRule优化后执行计划,针对edge label的过滤转移到MatchEdge中进行
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user) where =(a.id, 1) -[e:knows]-(b:user)])
LogicalGraphScan(table=[default.g0])
🍀支持增量匹配算子
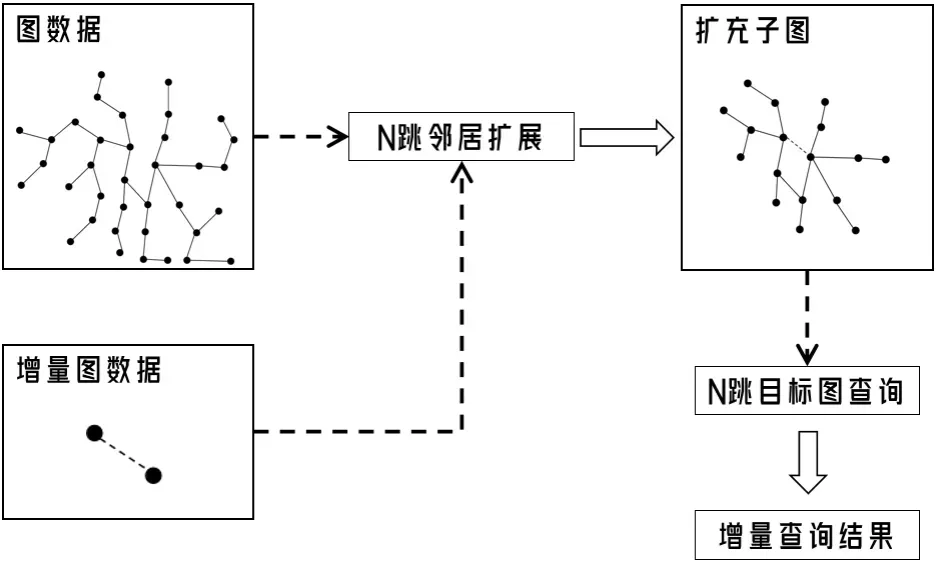
在动态图场景中,数据往往不是全部一批到来,而会源源不断地进行输入和计算,图的点边不断地从数据源读取,进行构图,从而形成增量图。对于某一批新增的点边,构成了一个新的版本的图,如果重新对全图(即当前所有点边)进行图遍历,开销较大。当前版本中使用了一种基于子图扩展的增量图匹配方法,通过子图扩展,来扩展每次增量的触发起点,尽可能地只对增量的数据进行查询:
- 支持增量匹配逻辑,通过反向传播来扩展每次 window 新增数据的触发起点。
- 通过在 dsl 或高阶代码中设置
geaflow.dsl.graph.enable.incr.traversal参数为 true 开启增量计算逻辑。
开启示例如下:
QueryTester.build()
.withConfig(FrameworkConfigKeys.BATCH_NUMBER_PER_CHECKPOINT.getKey(), "1")
.withQueryPath(queryPath)
.withConfig(DSLConfigKeys.ENABLE_INCR_TRAVERSAL.getKey(), "true")
.withConfig(DSLConfigKeys.TABLE_SINK_SPLIT_LINE.getKey(), lineSplit)
.execute();
✨ 历史版本回顾
我们回顾上一版,v0.6.3 版本在 v0.5.2 版本基础之上实现了一些重要功能特性,其中包括:
- ✨实现了 OSS/DFS/S3 标准化接口,接入主流云存储:支持开源 OSS/DFS/S3 等 remote 分布式存储,同时标准化了接口,便于按需快速扩展其它外部分布式存储系统。
- ✨支持标准 Match 算子:支持标准 ISO-GQL Match 语法及算子。
- ✨Aliyun ODPS 表的读写能力:支持 Aliyun ODPS 插件,提供 ODPS 表的读写能力。
- ✨兼容开源 Ray 生态:引擎支持开源 Ray 版本,同时 console 平台支持将任务提交到 Ray 集群。
- ✨DSL 支持时序能力:DSL 侧支持时间感知的数据处理、提供动态图与时序结合的能力。
- ✨Shuffle 支持反压优化:通过滑动窗口的方式进行数据传输和实现反压能力。
- ✨GeaFlow 流图性能测试:新增了 GeaFlow Vs Spark/Flink 的 demo 和性能测试报告。
✨ 致谢
感谢所有贡献者使这次发布成为可能!