Streaming Graph Computing Engine Apache GeaFlow (Incubating) v0.6.4 Released: Supports Relational Access to Graph Data, Incremental Matching Optimizes Real-Time Processing
March 2025 saw the release of streaming graph computing engine Apache GeaFlow (Incubating) v0.6.4. This version implements multiple significant feature updates, including:
- 🍀 Experimental support for storing GeaFlow graph data in Paimon data lake
- 🍀 Enhanced graph data warehouse capabilities: Supports relational access to graph entities
- 🍀 Unified memory manager support
- 🍀 RBO rule extensions: New MatchEdgeLabelFilterRemoveRule and MatchIdFilterSimplifyRule
- 🍀 Support for incremental matching operators
✨ New Features
🍀 Apache GeaFlow (Incubating) Graph Storage Extended to Support Paimon Data Lake (Experimental)
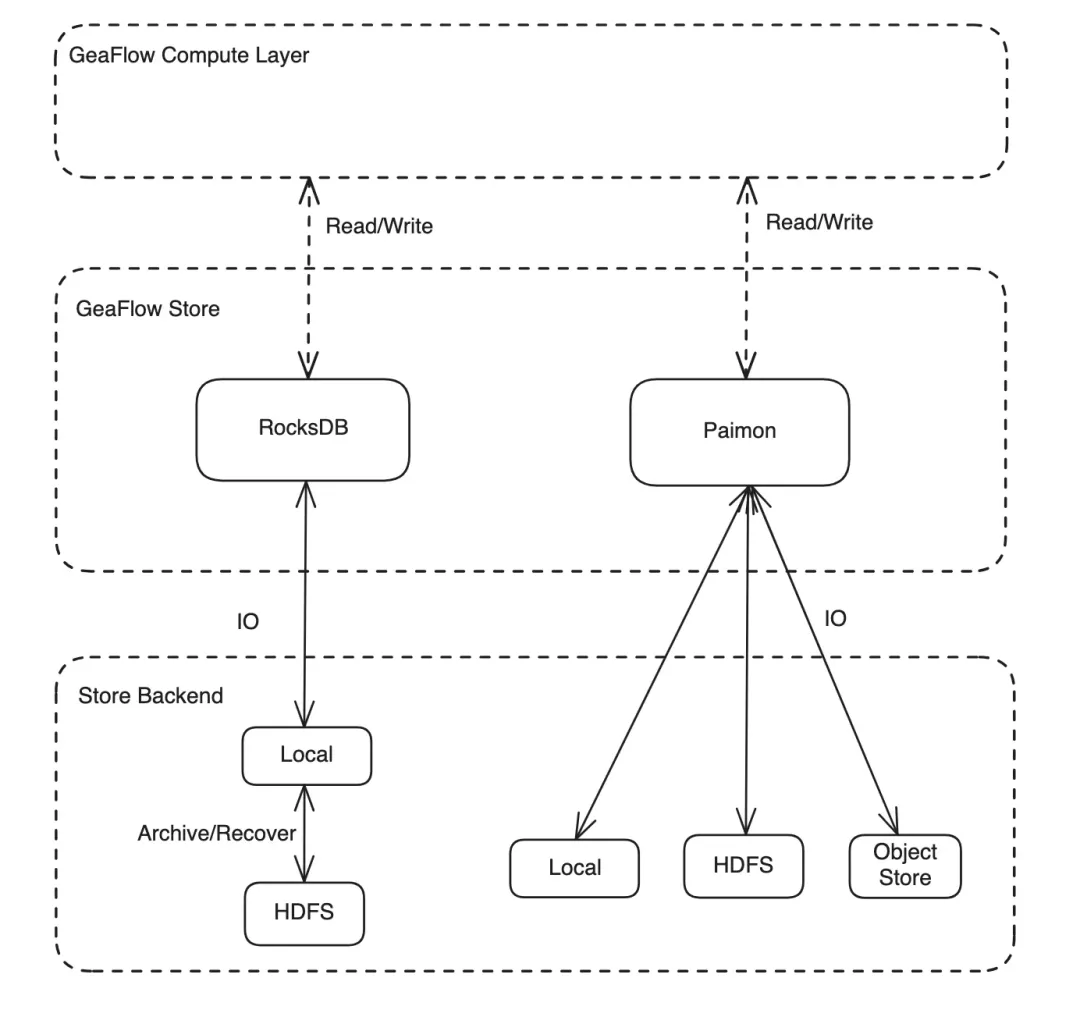
To enhance GeaFlow's data storage system scalability, real-time processing capabilities, and cost efficiency, this update adds support for Apache Paimon. As a next-generation streaming data lake storage format, Paimon differs significantly in design philosophy and features from RocksDB, previously used by GeaFlow:
- Supports object storage/HDFS distributed storage, natively adapting to cloud-native environments. This enables storage-compute separation, reduces hardware dependencies, and supports elastic scaling.
- Supports primary key table LSM compaction and incremental updates, meeting real-time data update demands.
- Columnar storage + statistical indexing (Z-Order, Min-Max, etc.), enabling efficient data pruning and OLAP query acceleration.
In this update, GeaFlow adds support for Paimon storage (currently experimental):
- Allows storing user graph data in Paimon data lake via GeaFlow.
- Current limitations: Only supports local filesystem as Paimon backend; recoverability not yet supported; dynamic graph data storage not yet supported.
- Configure the storage path via the parameter
geaflow.store.paimon.options.warehouse(default:"file:///tmp/paimon/").
The current Apache GeaFlow (Incubating) storage architecture is shown below:
🍀 Graph Data Warehouse Capability Expansion: Supports Relational Access to Graph Entities
In traditional relational databases, multi-table JOIN queries often require complex SQL statements, hindering development efficiency and struggling with performance for ad-hoc analysis of massive interconnected data. Addressing this pain point, Apache GeaFlow (Incubating) introduces innovative SQL support that automatically translates complex SQL JOIN statements into graph path queries—no Graph Query Language (GQL) needed. This version offers two SQL syntax features:
- Querying Vertices/Edges as Source Tables:
- The
TableScanToGraphRuleidentifies vertices/edges within SQL statements, enabling users to query graph entities like standard SQL table scans. - Example (
studentis a vertex entity in graphg_student):USE GRAPH g_student;
INSERT INTO table_scan_001_result
SELECT AVG(age) AS avg_age FROM student;
- Equi-Joins on Vertices and Associated Edges:
- The
TableJoinTableToGraphRuleidentifies JOIN operators in SQL, enabling relational-style joins directly on graph data. - Example (
studentis a vertex,selectCourseis an outgoing edge associated withstudent):USE GRAPH g_student;
INSERT INTO vertex_join_edge_001_result
SELECT s.id, sc.targetId, sc.ts
FROM student s JOIN selectCourse sc ON s.id = sc.srcId
WHERE s.id < 1004
ORDER BY s.id, targetId;
🍀 Unified Memory Manager Support
Previously, Apache GeaFlow (Incubating) lacked centralized memory management. Apart from RocksDB using off-heap memory, all memory was on-heap, leading to significant GC pressure under heavy loads. Network shuffling also involved multiple data copies, reducing efficiency.
The new Unified Memory Manager governs memory allocation, release, and monitoring across modules (shuffle, state, framework) for both on-heap and off-heap memory. Key capabilities include:
- Unified On-heap/Off-heap Management: Abstracts memory access via
MemoryView, shielding users from the underlying type. Off-heap chunks are pre-allocated (default chunk size: 30% of-Xmx, configurable viaoff.heap.memory.chunkSize.MB) and support dynamic resizing. - Compute & Storage Memory Unification: Memory is divided into three pools:
- Shuffle: Dedicated 10% of off-heap.
- State: Dedicated 10% of off-heap.
- Default: 80% of off-heap; dynamically usable by Shuffle or State as needed.

🍀 RBO Rule Extensions: New EdgeLabel and IdFilter Optimization Rules
Two new rule-based optimization (RBO) rules simplify execution plans for common GQL MATCH patterns:
MatchEdgeLabelFilterRemoveRule: Simplifies plans whereWHEREfilters edges by label (~label) after theMATCHclause. Pushes the filter into the edge matching step.MatchIdFilterSimplifyRule: Simplifies plans whereMATCHpatterns filter vertices byid. Pushes theidfilter into the vertex matching step.
- Enabled by default.
- Example 1 (IdFilter Simplification):
// Original GQL
MATCH (a:user WHERE id = 1)-[e:knows]-(b:user)
RETURN a.id AS a_id, e.weight AS weight, b.id AS b_id
// Optimized Plan: id filter moved into MatchVertex
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user)-[e:knows]-(b:user)])
LogicalGraphScan(table=[default.g0]) - Example 2 (EdgeLabel Filter Removal):
// Original GQL
MATCH (a:user WHERE id = 1)-[e:knows]-(b:user) WHERE e.~label = 'knows' OR e.~label = 'created'
RETURN a.id AS a_id, e.weight AS weight, b.id AS b_id
// Optimized Plan: edge label filter moved into MatchEdge
LogicalProject(a_id=[$0.id], weight=[$1.weight], b_id=[$2.id])
LogicalGraphMatch(path=[(a:user WHERE =(a.id, 1)) -[e:knows]-(b:user)])
LogicalGraphScan(table=[default.g0])
🍀 Support for Incremental Matching Operator
In dynamic graph scenarios, data arrives continuously. New points/edges incrementally build the graph. Reprocessing the entire graph for each update is costly. v0.6.4 introduces an Incremental Matching Operator based on subgraph expansion:
- Utilizes backpropagation to determine starting points triggered by each window of new data, minimizing processing to only affected regions.

- Enable via DSL or high-level code by setting
geaflow.dsl.graph.enable.incr.traversaltotrue.QueryTester.build()
.withConfig(FrameworkConfigKeys.BATCH_NUMBER_PER_CHECKPOINT.getKey(), "1")
.withQueryPath(queryPath)
.withConfig(DSLConfigKeys.ENABLE_INCR_TRAVERSAL.getKey(), "true") // Enable Incremental
.withConfig(DSLConfigKeys.TABLE_SINK_SPLIT_LINE.getKey(), lineSplit)
.execute();
✨ Previous Version Recap (v0.6.3)
Key features introduced in v0.6.3 (building on v0.5.2) include:
- ✨ OSS/DFS/S3 Standardized Interface: Access for mainstream cloud storage; extensible architecture.
- ✨ Standard
MATCHOperator: Full support for ISO-GQLMATCHsyntax. - ✨ Aliyun ODPS Read/Write: Plugin support for Alibaba Cloud ODPS tables.
- ✨ Open-Source Ray Compatibility: Engine supports open-source Ray; console submits tasks to Ray clusters.
- ✨ DSL Temporal Capabilities: Time-aware data processing & dynamic graph + temporal features.
- ✨ Shuffle Backpressure Optimization: Sliding window-based data transfer and backpressure implementation.
- ✨ GeaFlow Stream-Graph Benchmarks: Added performance demo/reports vs. Spark/Flink.
✨ Acknowledgments
Thank you to all contributors for making this release possible!