Join Performance Revolution: Graph Data Warehouse Makes SQL Analysis Faster Than Ever

Author: Lin Litao
1. Introduction: The Dilemma and Breakthrough in Traditional Data Warehouses
1. Contextual Problem: When Data Association Becomes a Business Pain Point
- Financial Anti-Fraud Scenario: In anti-fraud analysis, complex multi-layered fund chain mining often relies on multi-table JOIN operations for intricate multi-hop tracking. Analyst teams spend days writing SQL scripts, and the final query can take hours — by which time the funds have already been laundered. This reveals a deep contradiction in traditional data warehouses: the misalignment between the relational paradigm and real-world networked business logic, often leading to high query latency and complex logic.
- Marketing Analysis Scenario: In analyzing marketing business relationships, identifying potential VIP customers through social connection chains requires advanced data analysis skills. Although tools like DeepInsight AI Copilot now allow users to quickly generate dimensions and metrics with 80% accuracy via large models and integrate them into self-service dashboards, these analyses often involve deep user associations, which perform poorly when expressed intuitively in SQL.
2. Data Constraints
Efficiency Constraint: When association levels exceed 3 hops, the time complexity of traditional JOIN operations grows exponentially. Analytical models centered around multi-table JOINs gradually lose their advantage and become a "shackle" to efficiency.
Expressiveness Constraint: Traditional SQL not only requires complex expressions but also struggles to intuitively represent graph topologies using the relational model.
Innovation Constraint: Business analysts often abandon graph technology stacks due to the need to learn GQL (Graph Query Language). The fragmented toolchain keeps graph analytics confined to technical departments, failing to empower front-line business teams.
3. Breakthrough Strategy: Core Value of the Graph Data Warehouse
(1) Lower Cognitive Costs
Users don’t need to understand graph database expertise. Complex graph association analysis can be performed through SQL operations, with the underlying system connected to a graph engine.
(2) Accelerate the Dimensional Upgrade of Data Value
Building on traditional SQL analysis, the graph data warehouse encapsulates graph algorithms like PageRank and Louvain as interpretable business metrics via a built-in algorithm repository. This enables the analysis of hidden complex patterns (e.g., closed-loop fund paths). Additionally, relationships can be instantly visualized as graph structures, moving away from the abstract nature of table-based associations in traditional warehouses, thereby expanding analytical boundaries.
(3) Break Through Performance Bottlenecks
Multi-table JOIN queries are transformed into graph path retrievals, leveraging the graph engine’s strength in relationship analysis. Performance can jump from minutes to seconds, with single-point analysis entering the millisecond level. Real-time updates of dynamic graph data provide a stark contrast to the lag of traditional batch processing models (T+1).
2. Technical Deep Dive: Core Technological Revolution of the Graph Data Warehouse
1. Schema Converter (ER → Graph)
For most non-expert users, lack of graph domain knowledge and unfamiliarity with graph modeling mindsets present significant challenges in solving business problems using graph computing systems. In business promotion, we found that automatically converting ER model descriptions of tables into graph models and providing users with an initial graph helps them get started quickly.
The Graph Data Warehouse Schema Converter automatically transforms the ER model (Entity-Relationship model) in traditional data warehouses into node and edge structures in a graph database, supporting unified modeling of physical tables, view tables, and dimension tables. Conceptually, a graph entity can be seen as a KV table generated from a selected column sequence in a relational table as the ID. During ER graph parsing, columns with equivalent values are treated as the same equivalence class, and the equivalence relationship is propagated across equivalent columns in different tables.
Thus, the model conversion algorithm can be summarized in three stages:
Stage 1: Semantic Analysis.Focus on selecting entity column sequences for ID composition, identifying entity/relationship semantics in tables, discovering cross-table equivalent columns (columns with equal value relationships), and supporting expression-based column processing. Among all possible solutions, the best-performing one in terms of storage performance, computational performance, and interpretability is selected as the graph foundation.
Stage 2: Structured Transformation.Focus on generating vertex/edge entities, merging vertex entities, and creating redundant edges when necessary to balance data redundancy and query performance. Virtual nodes are automatically created to bind relationships, and edge start/endpoints are configured.
Stage 3: Graph Assembly.All vertices are merged, and edges bound to start nodes are naturally merged. Endpoint binding is optional. For two different graph conversion schemes, a difference vector can be calculated — representing how all tables map to entity changes.
Through algorithmic analysis of inter-table associations and automatic graph construction, this provides a basis for migrating data from its original storage location to the graph data warehouse. It also significantly reduces manual data modeling and DSL scripting efforts, enabling fast migration of traditional warehouse data to a graph warehouse with no manual intervention and immediate analysis readiness.
2. Data Pipeline: Materialized Data Interaction Capabilities
Similar to traditional data warehouses, the graph data warehouse leverages Apache GeaFlow (Incubating) engine capabilities and TuMaker’s mature business platform to provide data task orchestration capabilities — organizing multiple data processing tasks (like data extraction, transformation, and loading) in a logical sequence and executing them automatically. Key features include visual interfaces, task scheduling, event triggers, error handling, monitoring and logging, version control and rollback, and intelligent cluster resource scheduling.
With the help of the Schema Converter, a materialization plan from table storage to graph storage can be generated, building a data pipeline between traditional and graph data warehouses. Based on the table-to-graph materialization plan, the system can automatically generate data sync task orchestrations according to actual business configurations like acceleration tables, relationships, fields, and permissions. These are then scheduled via the graph warehouse platform to achieve seamless data migration. Subsequent real-time updates and incremental syncs can be completed within ten minutes.
The data pipeline integrates deeply with mainstream big data ecosystems like ODPS/Hive/Paimon. It achieves full lifecycle data management through a three-tier architecture: at the data access layer, it automatically captures table changes, generates materialization plans, and syncs incremental mappings from tables to graph entities, currently managing graph data at the 10TB scale; at the conversion engine layer, it fully automates DSL task orchestration and schedules them to clusters; at the storage optimization layer, it supports proprietary and open-source graph storage solutions like CStore/GraphDB/RocksDB, validated in trillion-edge-scale super-large business graphs. Additionally, hot data preloading maintains second-level query response times even at the TB scale, truly enabling a full-stack transition from relational to graph warehouses, with SQL running on top of graphs.
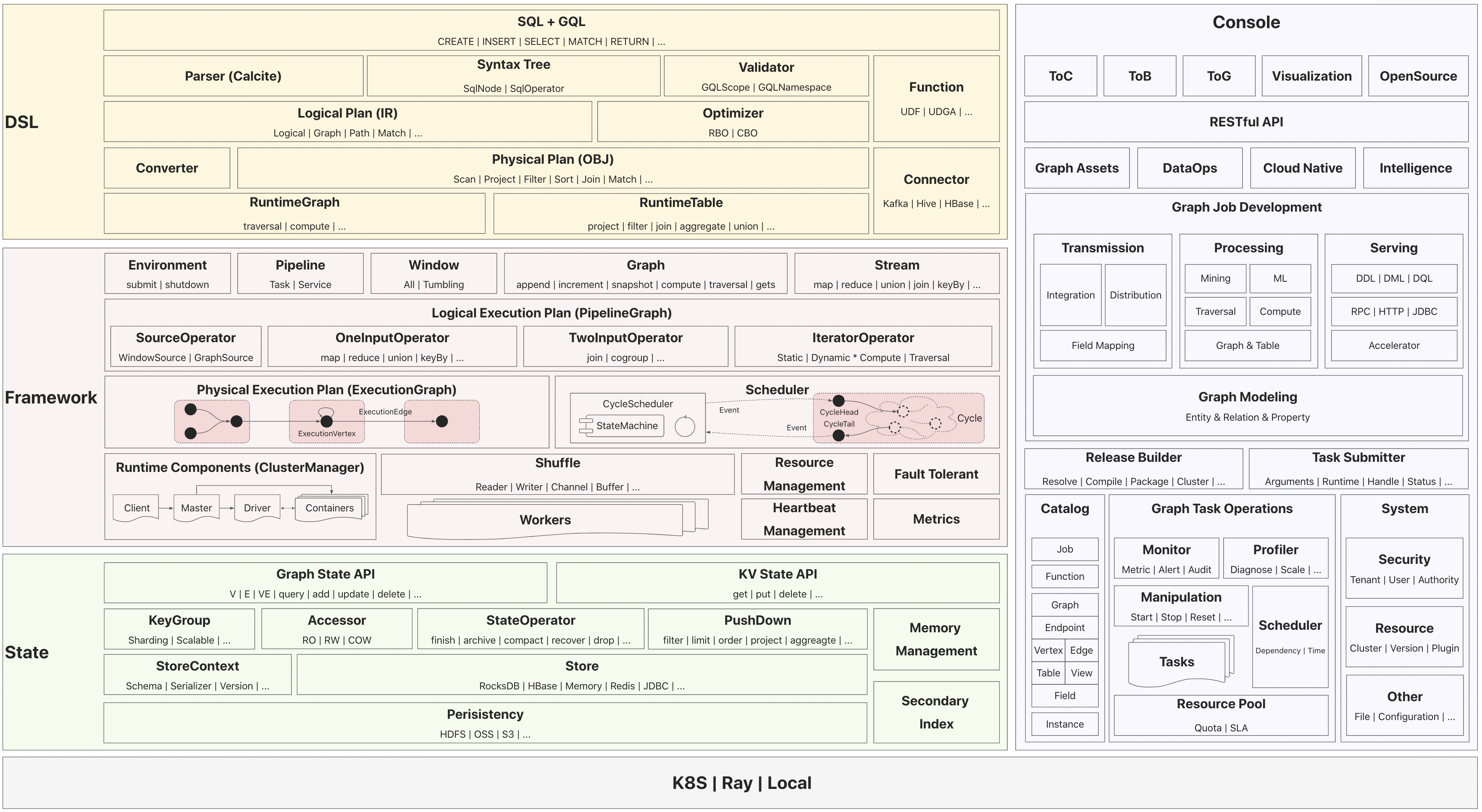
Figure 4: Open-Source Technical Architecture Overview
3. SQL-GQL Translation Engine
In traditional relational databases, multi-layer table join queries often require complex JOIN statements, which are not only inefficient to develop but also struggle to meet the demands of ad-hoc analysis of massive associated data. To address this pain point, we introduced an innovative SQL-GQL translation engine that automatically converts complex SQL JOINs into graph path queries without requiring users to learn graph query languages (GQL). This eliminates user perception of graph complexity while leveraging the graph engine for performance optimization.
Unlike SQL, which operates on two-dimensional tables based on the relational model, GQL's query structure and semantics align with graph data characteristics, especially in linearization and nested processing of query logic. Converting SQL queries to GQL involves syntax structure mapping, data model mapping, and execution logic reconstruction. The core challenge is how to transform set operationsbased on the relational model into linear path traversalsbased on the graph model, while avoiding the cost of nested queries and suboptimal graph computation order.
Compared to traditional SQL queriesthat may take minutes to analyze user relationships through three table joins, graph path queries can complete the same task in seconds.This engine has been validated in typical business scenarios like short video analysis, membership growth, and customer rights services. In the future, it will expand to support complex subqueries and expression operations, allowing more developers to unlock graph computing power without crossing technical barriers.
3. Technical Advantages and Application Scenarios
3.1 Underlying Logic of Efficiency Gains
In relational analysis scenarios, the graph data warehouse’s breakthrough performance stems from two core technological innovations.
First, the graph storage model optimizes physical structures, fundamentally changing data organization. Traditional relational databases store association information in foreign key tables, requiring frequent indexing and data reorganization during multi-table JOINs. In contrast, the graph model uses native key aggregation storage, storing entity attributes and their relationships as physically adjacent "node-edge" structures. With cache preloading, traversal complexity drops from O(n²) to O(n), and key processing complexity from O(n) to O(1).
Second, graph traversal algorithms establish a new query paradigm. Unlike relational databases' set-based batch processing, graph engines use depth-first or breadth-first path traversal, dynamically pruning branches to avoid inefficiencies. This ensures that multi-layer link tracking remains at the second level, while traditional SQL approaches often hit minute-level delays on large tables. Crucially, graph traversal supports real-time incremental computation, demonstrating strong scalability when new records are added.
3.2 User Value Proposition
As a next-generation data infrastructure, the graph data warehouse pioneers a "one graph, multiple uses" paradigm. Users can perform standard analysis through familiar SQL interfaces while integrating underlying engines with existing infrastructure. When deeper analysis is needed, they can switch to professional graph query languages like GQL or Gremlin. This dual-mode compatibility is especially valuable when supporting diverse analytical needs with the same data assets.
At the algorithm level, the system’s built-in graph computing engine transcends traditional warehouse limitations and opens interfaces for custom graph algorithm development within the open-source ecosystem. For example, traditional PageRank algorithms can identify influential nodes in social networks for targeted marketing; Weakly Connected Components (WCC) can detect anomalous communities in billion-scale transaction data. Through standardized APIs, users can perform trillion-edge-scale data mining without needing to understand distributed computing or data graphing processes.
Compared to traditional data warehouses, the graph data warehouse achieves generational leaps in three dimensions: performance (1–2 orders of magnitude faster), usability (eliminating graph learning barriers via SQL-GQL auto-conversion), and analytical depth (supporting algorithmic analysis and hidden relationship discovery).
4. Future Outlook
As a core carrier of next-generation data infrastructure, we plan to gradually open-source core capabilities like the graph storage engine, graph computing framework engine, and SQL-GQL translation module to build a developer-driven technical ecosystem. In 2023, we first open-sourced the streaming graph computing engine Apache GeaFlow (Incubating). In Q3 2025, we will release a standardized graph data analysis platform, high-performance graph computing engine, and support community developers in building connectors for heterogeneous data sources. This open collaboration accelerates technical iteration and positions the product as the best practice platform for the ISO/IEC 39075 GQL international standard, driving SQL-GQL hybrid queries to become an industry norm.
On the technical evolution front, the next-generation engine will break through dynamic streaming graph computing bottlenecks to support trillion-edge incremental updates. By integrating vectorized computing engines, it can jointly query property graphs and vector graphs to meet AIGC-era multimodal analysis needs and enable revolutionary experiences like generating graph queries directly from natural language. Industry applications are rapidly expanding, and the graph data warehouse will soon become the core engine for most enterprise relational data analysis and intelligent decision-making.
Let me know if you'd like a version formatted for a blog, documentation, or presentation!