Stream4Graph: Incremental Computation on Dynamic Graphs
Author: Zhang Qi
It's well known that when we need to perform correlation analysis on data, we typically use SQL join operations. However, Cartesian product calculations during SQL joins require maintaining a large number of intermediate results, which significantly impacts overall data analysis performance. In contrast, graph-based approaches maintain data correlations, transforming correlation analysis into graph traversal operations and greatly reducing the cost of data analysis.
However, with the continuous growth in data scale and increasing demand for real-time processing, efficiently solving real-time computation problems on large-scale graph data has become increasingly urgent. Traditional computing engines such as Spark and Flink are gradually falling short of meeting the growing business demands for graph data processing. Therefore, designing a real-time processing engine tailored for large-scale graph data will bring significant advancements to big data processing technologies.
Stream graph computing engine Apache GeaFlow (Incubating), which combines the technical advantages of graph processing and stream processing. It implements incremental computation capabilities on dynamic graphs, enhancing real-time performance in high-performance correlation analysis. In the following sections, we will introduce the characteristics of graph computing technology, how the industry addresses large-scale real-time graph computing challenges, and GeaFlow's performance in dynamic graph computation.
1. Graph Computing
A graph is a mathematical structure composed of nodes and edges. Nodes represent various entities such as people, locations, objects, or concepts, while edges represent the relationships between these nodes. For example:
- Social media:Nodes can represent users, and edges can represent friendships.
- Web pages:Nodes represent web pages, and edges represent hyperlinks.
- Transportation networks: Nodes represent cities, and edges represent roads or air routes.
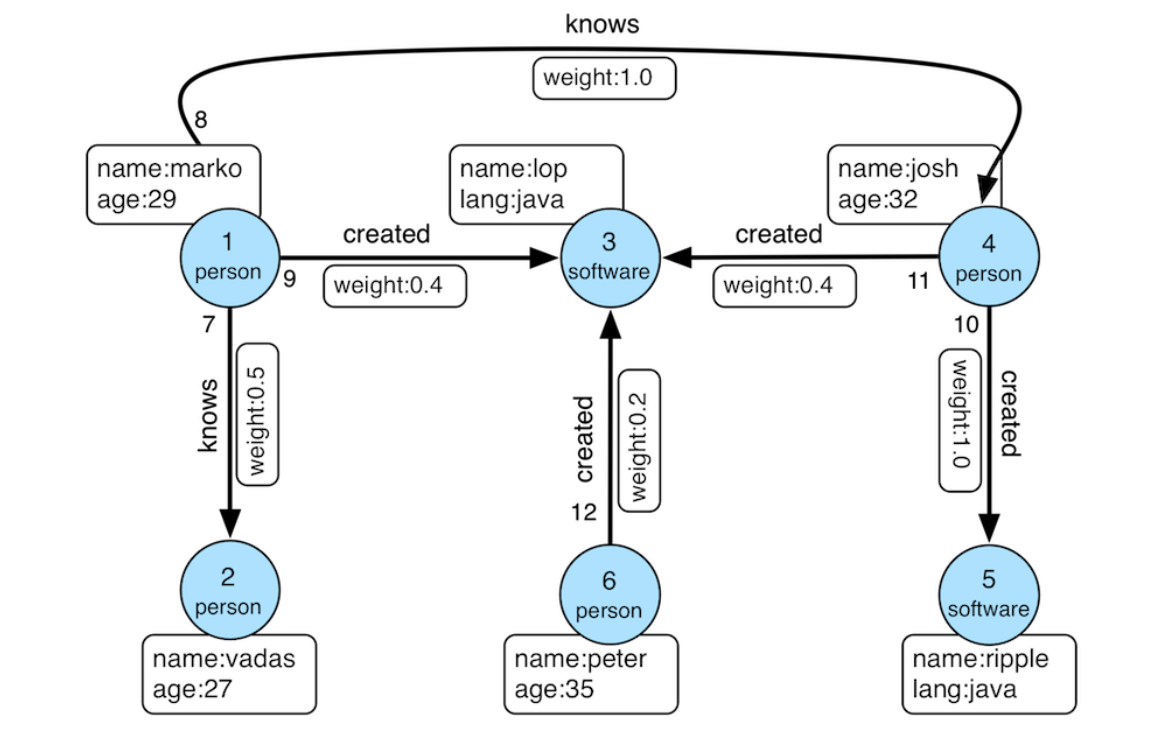
Graphs inherently represent the connections between nodes, and based on these relationships, we can use nodes and edges to process, analyze, and mine information, helping us understand relationships and patterns in complex systems. The computational activities conducted on graphs are referred to as graph computing. Graph computing has many applications, such as identifying user connections and discovering community structures through social network analysis, calculating web page rankings by analyzing hyperlink relationships, and recommending relevant content and products by building relationship graphs based on user behavior and preferences.
Let's take a simple social network analysis algorithm—Weakly Connected Components (WCC)—as an example. WCC helps us identify "friend circles" or "communities" among users. For instance, on a social platform, a group of users who interact through likes, comments, or follows forms a large weakly connected component, while some users may not be connected to this large component, forming smaller weakly connected components.
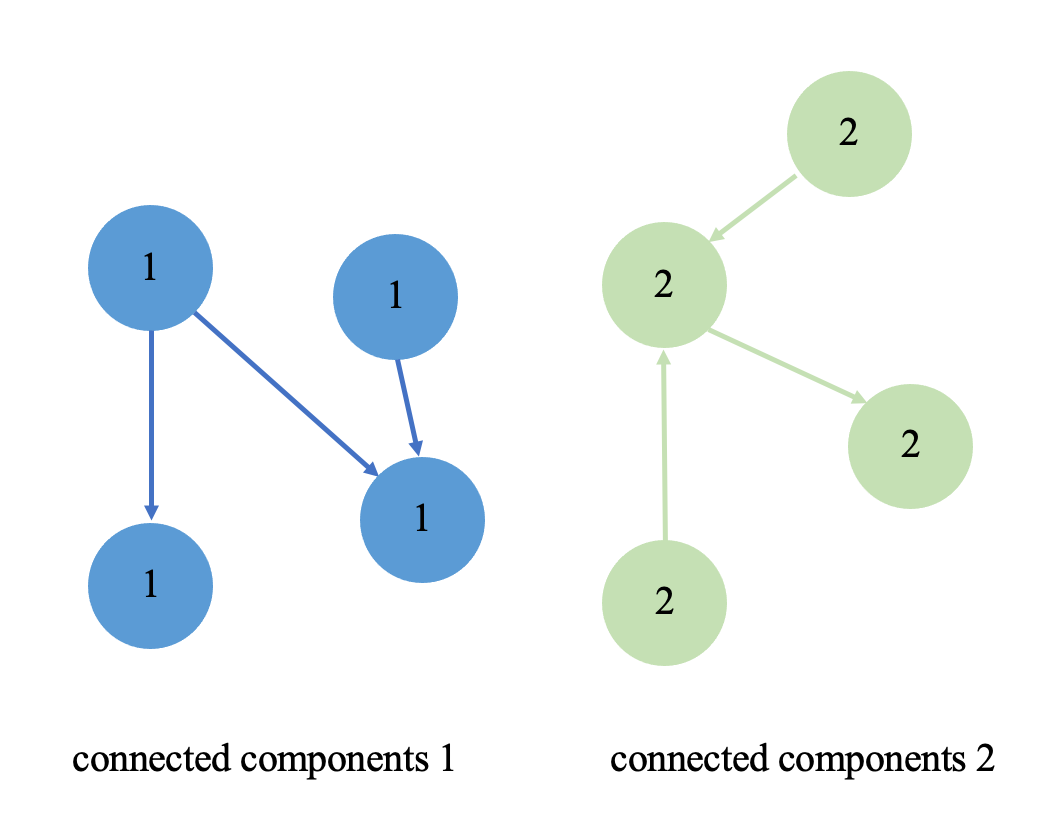
If we were to build a WCC algorithm based solely on the small graph above, it would be very simple—we could just construct a basic node-edge structure on a personal PC and perform graph traversal. However, if the graph scale expands to hundreds of billions or even trillions, we would need to use large-scale distributed graph computing engines to handle it.
2. Distributed Graph Computing: Spark GraphX
Graph processing generally falls into two categories: graph computing engines and graph databases. Graph databases include Neo4j, TigerGraph, etc., while graph computing engines include Spark GraphX, Pregel, etc. In this article, we mainly discuss graph computing engines, using Spark GraphX as an example. Spark GraphX is a component of Apache Spark specifically designed for graph computing and analysis. GraphX combines Spark’s powerful data processing capabilities with the flexibility of graph computing, extending Spark’s core functionality and providing users with a unified API for processing graph data.
How does Spark GraphX handle graph algorithms? GraphX extends Spark RDD by introducing a directed multigraph where both nodes and edges carry attributes, providing users with a vertex-centric parallel abstraction similar to the Pregel computing model. Users need to provide GraphX with the original graph, initial messages, core computation logic (vprog), message-sending component (sendMsg), and message-merging component (mergeMsg). At the start of the computation, GraphX activates all vertices for initialization. Then, based on the user-provided sendMsg component, it determines which vertices to send messages to. In subsequent iterations, only vertices that receive messages are activated for further computation, repeating the process until no new vertices are activated or the maximum iteration count is reached, finally outputting the results.
def apply[VD: ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
{
var g = graph.mapVertices((vid, vdata) => vprog(vid, vdata, initialMsg))
// compute the messages
var messages = GraphXUtils.mapReduceTriplets(g, sendMsg, mergeMsg)
// Loop
var prevG: Graph[VD, ED] = null
var i = 0
while (isActiveMessagesNonEmpty && i < maxIterations) {
// Receive the messages and update the vertices.
prevG = g
g = g.joinVertices(messages)(vprog)
graphCheckpointer.update(g)
// Send new messages, skipping edges where neither side received
// a message.
messages = GraphXUtils.mapReduceTriplets(
g, sendMsg, mergeMsg, Some((oldMessages, activeDirection)))
}
}
In summary, users first need to convert raw tabular data from storage into node-edge data types in GraphX and then let Spark handle the processing. This is for offline processing of static graphs. However, in the real world, both the scale of graph data and the relationships between nodes are constantly changing, especially in the era of big data where changes occur rapidly. How to efficiently and real-time process dynamic graph data is a significant challenge.
3. Dynamic Graph Computing: Spark Streaming
For processing dynamic graphs, a common solution is the Spark Streaming framework, which can consume data from various sources and process it. It extends Spark’s core API to enable high-throughput, fault-tolerant real-time stream data processing.

As shown in the figure above, this is the process of Spark Streaming handling real-time data. First, each Receiver in Spark receives a real-time message stream, parses and segments the messages, and then stores the generated graph data in each Executor. When data accumulates to a certain batch, a full-scale computation is triggered, and the final results are output to the user. This is known as the snapshot-based graph computing approach.
However, this approach has a significant drawback: it involves redundant computation. For example, if we need to compute once per hour, using Spark would require not only computing the current window’s data but also backtracking all historical data, leading to a large amount of redundant computation. Therefore, we need a graph computing solution that supports incremental computation.
4. Incremental Dynamic Graph Computing: Apache GeaFlow (Incubating)
We know that in traditional stream computing engines like Flink, the processing model allows the system to handle continuously incoming data events. When processing each event, Flink can evaluate changes and execute computations only on the changed parts. This means that in incremental computing, Flink focuses on the latest incoming data rather than the entire dataset. Inspired by Flink’s incremental computing, we developed the incremental graph computing system Apache GeaFlow (Incubating) (also known as the stream graph computing engine), which effectively supports incremental graph iterative computation.
How does Apache GeaFlow (Incubating) implement incremental graph computing? First, real-time data is input into GeaFlow through connectors. GeaFlow generates internal node-edge structure data based on the real-time data and inserts this data into the underlying graph. Nodes involved in the real-time data within the current window are activated, triggering graph iterative computation.
Using the WCC algorithm as an example, for the connected components algorithm, in a time window, each edge’s src id and tar id vertices are activated. In the first iteration, their id information is sent to neighboring nodes. If a neighboring node receives the message and finds that it needs to update its information, it continues to notify its neighbors; otherwise, its iteration terminates.

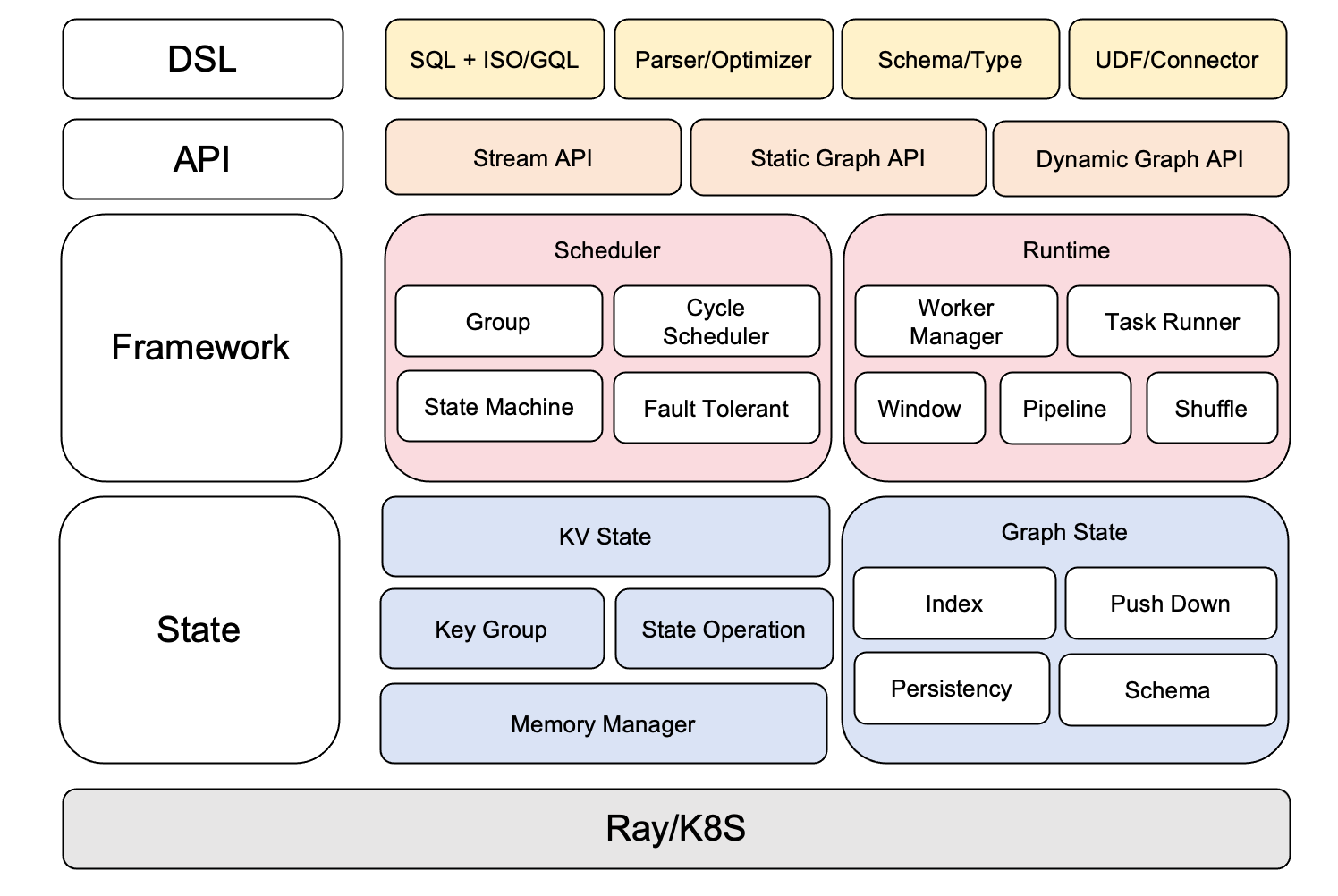
5. Apache GeaFlow (Incubating) Architecture Overview
The GeaFlow engine consists of three main parts: DSL, Framework, and State. It also provides users with Stream API, Static Graph API, and Dynamic Graph API. The DSL layer is responsible for parsing and optimizing graph query languages like SQL+ISO/GQL, as well as schema inference. It also supports various Connectors such as Hive, Hudi, Kafka, and ODPS. The Framework layer handles runtime scheduling, fault tolerance, shuffle, and coordination of components. The State layer is responsible for storing underlying graph data and persistence, as well as performance optimizations like indexing and predicate pushdown.
6. GeaFlow Performance Testing
To verify GeaFlow’s incremental graph computing performance, we designed the following experiment. A batch of data is input into the computing engine in fixed time windows. We use both Spark and GeaFlow to compute the connected components algorithm on the full graph and compare the computation time. The experiment was conducted on 3 machines with 24 cores and 128G memory each. The dataset used is the public soc-Livejournal dataset, and the graph algorithm tested is the Weakly Connected Components (WCC) algorithm. We use 500,000 data entries as a computation window, and each time 500,000 entries are input, a graph computation is triggered.
As a batch processing engine, Spark must perform full computations on both incremental and historical data for each batch window, regardless of the window size. On Spark, we can directly call the built-in WCC algorithm in Spark GraphX for computation.
object SparkTest {
def main(args: Array[String]): Unit = {
val iter_num: Int = args(0).toInt
val parallel: Int = args(1).toInt
val spark = SparkSession.builder.appName("HDFS Data Load").config("spark.default.parallelism", args(1)).getOrCreate
val sc = new JavaSparkContext(spark.sparkContext)
val graph = GraphLoader.edgeListFile(sc, "hdfs://rayagsecurity-42-033147014062:9000/" + args(2), numEdgePartitions = parallel)
val result = graph.connectedComponents(10)
handleResult(result)
print("finish")
}
def handleResult[VD, ED](graph: Graph[VD, ED]): Unit = {
graph.vertices.foreachPartition(_.foreach(tuple => {
}))
}
}
GeaFlow supports SQL+ISO/GQL graph query languages. We used the graph query language to call GeaFlow’s built-in incremental WCC algorithm for testing. The graph query language code is as follows:
CREATE TABLE IF NOT EXISTS tables (
f1 bigint,
f2 bigint
) WITH (
type='file',
geaflow.dsl.window.size='16000',
geaflow.dsl.column.separator='\t',
test.source.parallel = '32',
geaflow.dsl.file.path = 'hdfs://xxxx:9000/com-friendster.ungraph.txt'
);
CREATE GRAPH modern (
Vertex v1 (
id int ID
),
Edge e1 (
srcId int SOURCE ID,
targetId int DESTINATION ID
)
) WITH (
storeType='memory',
shardCount = 256
);
INSERT INTO modern(v1.id, e1.srcId, e1.targetId)
(
SELECT f1, f1, f2
FROM tables
);
INSERT INTO modern(v1.id)
(
SELECT f2
FROM tables
);
CREATE TABLE IF NOT EXISTS tbl_result (
vid bigint,
component bigint
) WITH (
ignore='true',
type ='file'
);
use GRAPH modern;
INSERT INTO tbl_result
CALL inc_wcc(10) YIELD (vid, component)
RETURN vid, component
;
The figure below shows the experimental results of the connected components algorithm using both methods. With 500,000 data entries per window, Spark involves a lot of redundant computation because it must backtrack all historical data. GeaFlow, however, only activates the nodes and edges involved in the current window for incremental computation, completing each window's computation within seconds with stable performance. As data volume increases, Spark's computation delay grows proportionally due to the increasing amount of historical data to backtrack. In contrast, GeaFlow’s computation time also slightly increases but remains at the second level.

7. Summary
Traditional graph computing solutions (e.g., Spark GraphX) have redundant computation issues in near real-time scenarios. Inspired by Flink's stream processing model and traditional graph computing, we have proposed a solution that supports incremental graph computing. Overall, GeaFlow has the following advantages:
- GeaFlow outperforms the Spark Streaming + GraphX solution in incremental real-time computing, especially on large-scale datasets.
- GeaFlow avoids redundant processing of full data through incremental computation, resulting in higher efficiency and shorter computation time without significant performance degradation.
- GeaFlow supports SQL+GQL hybrid processing languages, making it more suitable for developing complex graph data processing tasks.
The GeaFlow project is fully open-sourced. We have built some of the foundational capabilities of the stream graph engine. In the future, we hope to build a unified lakehouse processing engine for graph data based on GeaFlow to meet diverse big data correlation analysis needs. We are also actively preparing to join the Apache Foundation to enrich the open-source big data ecosystem. Therefore, we warmly welcome those interested in graph technology to join our community.
References
- Apache GeaFlow (Incubating) Project:https://github.com/apache/geaflow
- soc-Livejournal Dataset:https://snap.stanford.edu/data/soc-LiveJournal1.html
- Apache GeaFlow (Incubating) Issues:https://github.com/apache/geaflow/issues